semiIVreg: R package for semi-IV regression
Christophe Bruneel-Zupanc
last modified: 2025-01-31
semiIVreg.RmdOverview
This package provides estimation procedure with semi-IVs, as in Bruneel-Zupanc (2024).
In particular, the main function semiivreg() estimates the
marginal treatment effect (MTE) and marginal treatment response
(MTR).

Installation
The development version of semiIVreg is hosted on
GitHub here.
It can be conveniently installed via the install_github()
function from the remotes
package.
remotes::install_github("cbruneelzupanc/semiIVreg")The model
semiivreg estimates the marginal treatment effect (MTE)
and marginal treatment response (MTR) of the following model.
The potential outcomes are given by the semi-parametric model:
with selection rule
where
semi-IVs: (respectively ) are the semi-IVs excluded from (resp. ). Each and may contain several variables. Nonparametric identification requires that each contains at least one excluded variable (see Bruneel-Zupanc (2024)).
Covariates: are the covariates that affect both potential outcomes. By default, different effect of the covariates across alternatives, (i.e., ). To do so, include the covariates separately in both MTR formulas:
semiivreg(y~d|w0+x|w1+x, data). One can restrict the effect of to be the same across both potential outcomes (i.e., ). To do so, specify:semiivreg(y~d|w0|w1|x, data).Unobservables: and are general unobservables (may include several shocks, some may be the same across alternatives) affecting the outcomes. Generally normalize . is a scalar unobservable that affects the selection. The lower , the more likely one is to select into treatment. Nonparametric identification requires independence, i.e., .
For estimation here, we additionally assume additive separability of the covariates , i.e., that for both .
This assumption is not necessary for the identification, nor for the estimation. But it is a standard simplification that helps the estimation. See Carneiro, Heckman, and Vytlacil (2011), Brinch, Mogstad, and Wiswall (2017) or Andresen (2018) for comparable examples of the estimation of MTE with IVs.
Remark about the flexibility of the model: note that and can be flexible transformations (polynomial, splines) of specific variables, so the outcome equations are quite flexible (could also specify interactions between and ). The semi-parametric model main assumption here is the separability between the unobservables and , otherwise the model is as general as it can be.
Estimation procedure
The estimation procedure closely follows the counterpart estimation of MTE with standard IVs, see for e.g., Andresen (2018). The command estimates Marginal Treatment Responses (MTR) and Marginal Treatment Effects (MTE). Define the normalized unobserved resistance to treatment . Then, the MTRs are given by: where the last equalities comes from the fact that by the separability and independence, and then we just define .
Then, the Marginal Treatment Effects (MTE) are given by
Remark: the MTR and MTE are estimated at given covariates and
semi-IVs,
.
This is specified using ref_indiv. Or by default, it
computes the ‘average individual’ (and take reference level for
factor).
The estimation proceeds in two stages: first estimate the propensity to be treated, , and then the potential outcome treatment parameters.
1st stage: propensity score
Estimate the propensity score
of treatment selection of equation (3).
By default, the function
is given by the simple linear specification above, but the code allows
specifying any other first stage. For example:
By default, the estimation assumes a probit model for the
first stage (i.e., assumes
is normally distributed). However, you can specify other models (e.g.,
logit) using the firststage_model argument. In theory, any
specification for the first stage could be added, and it is even
possible to estimate the propensity score outside of the
semiivreg command (this feature is not implemented yet).
2nd stage: marginal treatment responses
Estimated objects
First, given estimated , the second stage estimates the following semi-parametric partially linear model for the potential outcomes where are control functions, equal to It is a partially linear model because the control functions are nonparametric and can be estimated more or less flexibly (see below).
Once the parameters and the flexible control function are estimated, we don’t need to estimate any other parameters to obtain the MTE and MTR. We only need to also obtain the derivative from the estimated . Indeed, define
Then, the Marginal Treatment Responses are given by:
and the Marginal Treatment Effects are:
Consequently, the estimation is about estimating the parameters and
.
Several estimation method est_method are implemented in
semiivreg(). We describe them below.
Method 1. Double residual regression, Robinson (1988)
The default method, implemented with
est_method="locpoly" is to run a double residual
regression, à la Robinson (1988), in
order to estimate the partially linear model. We implement it
similarly to the separate approach of Andresen
(2018) for the estimation of MTE with IVs. We estimate using a
separate approach, i.e., estimate separately on the treated and
untreated samples, by implementing the following steps:
Step 1. Estimate , and with a nonparametric local polynomial regression. To specify the bandwidth of the local polynomial regression, use
bw0orbw1. If not specified, the bandwidth are automatically computed using the method ofbw_method. The default being a fast"1/5rule, picking a bandwidth equal to 1/5th of the common support. We can also specify the degree of the polynomial withpol_degree_locpoly1. By default, equal to as recommended in Fan and Gijbels (1996) (order of the function we target ).Step 2. On each subsample, compute the residuals , and . Then, run the first residual regression, with a no-intercept OLS:
This regression on the subsample with , provides consistent estimates of and .
Indeed, the residual equation is equivalent to
and if we denote , we have , so the no-intercept residual OLS regression gives consistent estimates.Step 3. Construct , on the sample with , i.e., the outcome
net of the effectof the covariates. We have This yieldsStep 4. Estimate using a second nonparametric local polynomial regression of on . To specify the bandwidth of the local polynomial regression, use
bw_y0orbw_y1. If not specified, the bandwidth are automatically computed using the method ofbw_method. The default is again the arbitrary 1/5th rule, but we recommend using"mse-dpi"for the direct plug-in MSE optimal bandwidth from Fan and Gijbels (1996), as implemented by in thenprobustpackage (Calonico, Cattaneo, and Farrell (2019)) instead. We can also specify the degree of the polynomial withpol_degree_locpoly2. By default, equal to as recommended in Fan and Gijbels (1996) because we want to estimate the derivative, . Once we have , we can compute
Using the
and the estimated
,
we can compute the MTR on this subsample
,
as
Remark that the definition of
,
is equivalent to defining a more general shock that would include a
constant,
.
This is innoccuous and yield the same MTR/MTE in the end.
Once the MTR are estimated separately on both subsample, we can estimate the MTE:
Advantages. The main advantage of this double residual
regression is that it is robust to misspecification of the nonparametric
function, see Robinson (1988). However, it
still requires to specify the bandwidths. In order to obtain the
standard errors around the estimates, given that
is estimated in a first stage, we bootstrap the standard errors using
semiivreg_boot(). This function takes longer than the
default estimation which is almost instantaneous.
Method 2. Sieve estimation
An alternative method is to use sieve approach, implemented with
est_method="sieve", to estimate the second stage. The idea
is simply to specify the control function
as a flexible function of
,
using flexible functional form.
By default we use polynomial transformation of degree
pol_degree_sieve=5 for
and
.
Then, we estimate the second stage using a stacked regression of the
form:
We do it as a stacked regression and
not separately in order to allow to restrict some covariates to have the
same effect on both potential outcomes (e.g.,
).
Once we obtain , we proceed as before to obtain and the MTR/MTE. Because of the polynomial functional form, has a known functional form based on the estimated coefficients for , so it is very easy to compute.
Advantages. The main advantage of this sieve approach is
that it is faster and easier to implement (but "locpoly" is
also fast anyway). It also provides analytical standard errors. These
are wrong because they do not take into account that
is estimated in a first stage, but, if
is well estimated, the analytical standard errors should be very close
to the true one that we can obtain with the bootstrap in
semiivreg_boot().
The disadvantage is that it is less robust to misspecification of the
control function as a polynomial. Even though, as visible in this vignette,
it still works well in our examples, even if the underlying
is not a polynomial.
Method 3. Special Case with Homogenous Treatment Effects
Using est_method="homogenous", semiivreg()
can also estimate a restricted model where we assume that the treatment
effects are homogenous, i.e., the
,
only varies with the observable covariates, but is constant with respect
to
.
The homogenous treatment effect assumption is equivalent to imposing
that the underlying model corresponds to the general potential outcome
model (1)-(2), with the additional restriction that
.
It is estimated using a procedure similar to the sieve
approach with heterogenous treatment effects, but where we impose
additional known restriction on the control functions
and
in the second stage estimation. Indeed,
So, , and one can check that it yields .
Thus, the MTE is constant (, it cancels out), and equal to:
Note that the MTR still varies with
because
is not constant, only the MTE is.
Caution about the Estimated Standard Errors
By default, est_method="sieve" and
"homogenous” return analytic standard errors… But
not accounting for the fact that the propensity score is estimated in a
first stage in semiivreg. Thus, these are wrong (but the
bias is very small if the first stage is well estimated, see these
simulations for example).
Use semiivreg_boot to obtain ‘correct’ bootstrapped
confidence intervals.
Illustration with simulated Roy model
This illustrates what the semiivreg()command reports for
a semi-IV regression. By default, it reports the common support plot of
the propensity score and the estimated marginal treatment effects (MTE).
By default, the est_method = "locpoly" for Robinson (1988) double residual regression using
local polynomial regressions.
library(semiIVreg)
data(roydata) # load the data from a simulated Roy model
# semi-IV regression
semiiv = semiivreg(y~d|w0|w1, data=roydata)
#> Caution: the standard errors around the plot are not correct (underestimated) because of the multiple stages. For proper standard errors, run the bootstrap in semiivreg_boot().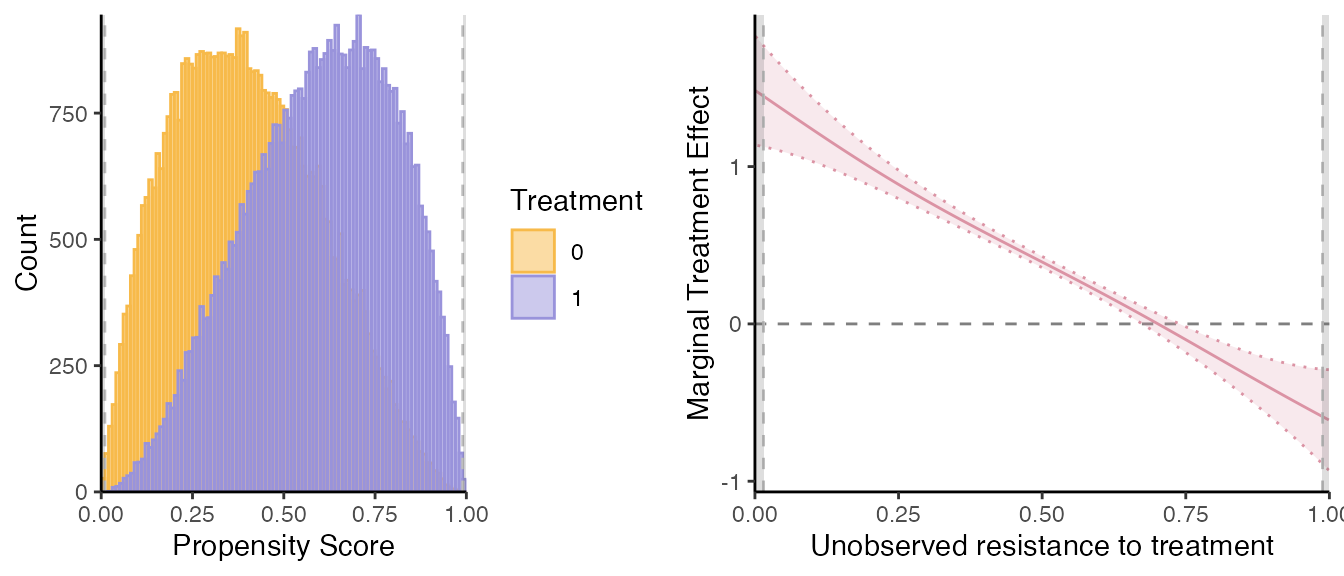
One can also easily extract a plot for the marginal treatment responses (MTR):
semiiv$plot$mtr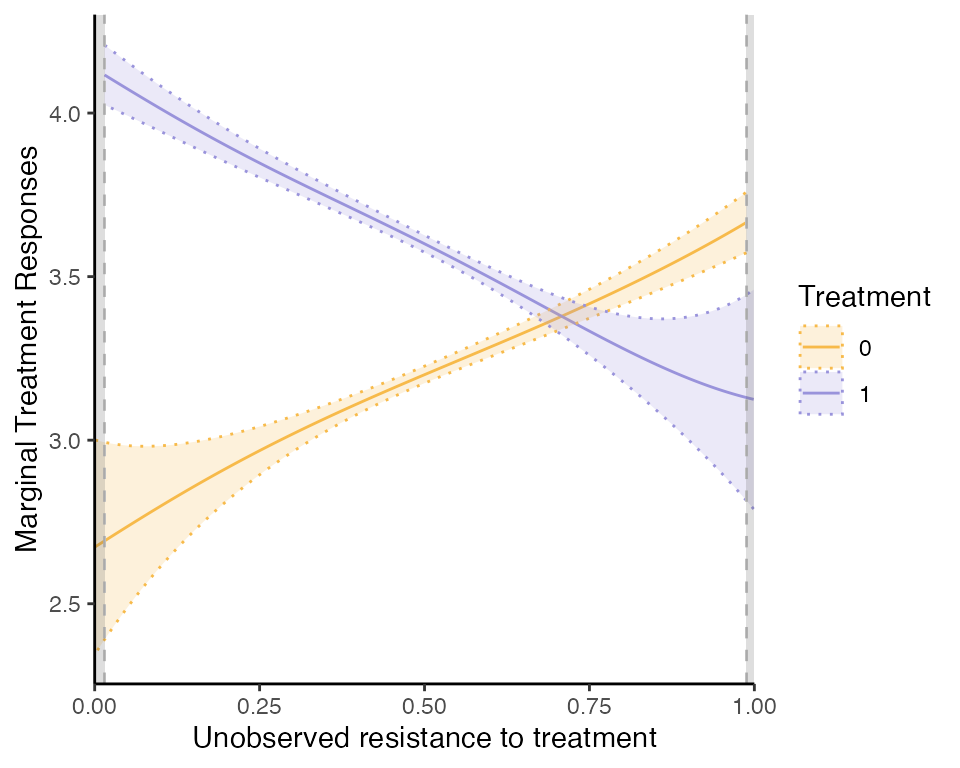
If one wants to use the sieve estimation method, simply run:
# semi-IV sieve regression
semiiv = semiivreg(y~d|w0|w1, data=roydata, est_method="sieve") 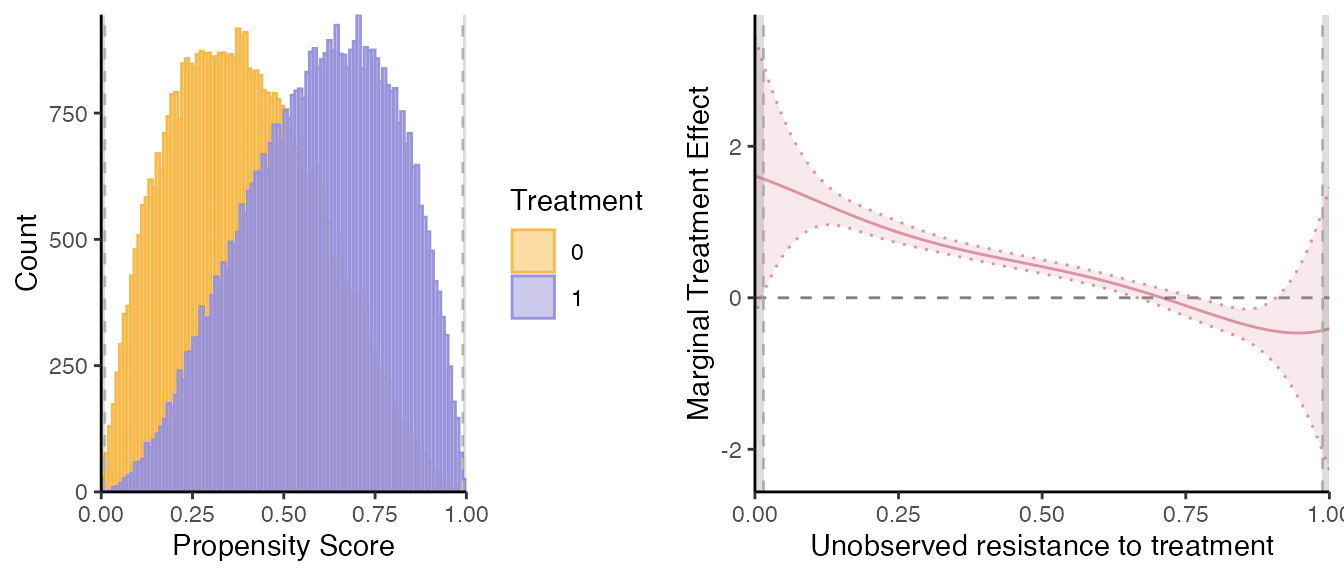
semiiv$plot$mtr
One advantage of the sieve is that it reports confidence interval (though wrong because do not take into account the first stage error) and also gives a functional form for the MTR and MTE, obtainable by running the code below.
semiiv$est$mtr0;
#> Variable Estimate Std_Error t_value p_value
#> 1 (Intercept) 2.7581424 9.298226e-01 2.96631018 0.003014676
#> 2 kd(v): v^1 -0.6853761 1.229132e+01 -0.05576099 0.955532327
#> 3 kd(v): v^2 12.0175370 5.692871e+01 0.21109801 0.832811220
#> 4 kd(v): v^3 -30.6762292 1.188494e+02 -0.25811010 0.796322466
#> 5 kd(v): v^4 31.3667340 1.142864e+02 0.27445721 0.783733849
#> 6 kd(v): v^5 -10.8461651 4.113650e+01 -0.26366279 0.792040318
#> 7 w0 0.8002338 3.955818e-03 202.29288041 0.000000000
semiiv$est$mtr1;
#> Variable Estimate Std_Error t_value p_value
#> 1 (Intercept) 4.3655568 0.142511442 30.63302633 3.985092e-205
#> 2 kd(v): v^1 -3.2471062 3.735243561 -0.86931580 3.846765e-01
#> 3 kd(v): v^2 4.2847118 26.418324185 0.16218711 8.711588e-01
#> 4 kd(v): v^3 4.5087919 75.498769743 0.05972007 9.523787e-01
#> 5 kd(v): v^4 -17.9382899 93.543557546 -0.19176403 8.479274e-01
#> 6 kd(v): v^5 11.5530308 41.752329058 0.27670387 7.820081e-01
#> 7 w1 0.4977251 0.003904244 127.48309330 0.000000e+00
semiiv$est$mte
#> Variable Estimate Std_Error t_value p_value
#> 1 (Intercept) 1.6074144 9.406804e-01 1.7087784 0.08749511
#> 2 kd(v): v^1 -2.5617302 1.284634e+01 -0.1994132 0.84193997
#> 3 kd(v): v^2 -7.7328252 6.275990e+01 -0.1232128 0.90193882
#> 4 kd(v): v^3 35.1850210 1.408021e+02 0.2498898 0.80267307
#> 5 kd(v): v^4 -49.3050239 1.476881e+02 -0.3338455 0.73849682
#> 6 kd(v): v^5 22.3991960 5.861287e+01 0.3821549 0.70234729
#> 7 + W1: w1 0.4977251 3.904244e-03 127.4830933 0.00000000
#> 8 - W0: w0 -0.8002338 3.955818e-03 -202.2928804 0.00000000Similarly, homogenous treatment effects will also provide a functional form estimation.
For more details, see the vignettes on estimation with heterogenous or homogenous treatment effects. Refer also to Bruneel-Zupanc (2024).